ML Basics: Linear Regression
Based on a Twitter Poll I’ll be doing a series on the basics of Machine Learning over the next few months. I plan to have a post out on the first Thursday of every month covering some algorithm or conceptual aspect of Machine Learning.
Machine Learning and Statistics have a lot in common. Both are interested in summarizing and finding patterns in data. It is necessary to have a solid grounding in stats to understand most machine learning textbooks. Sadly, most of the folks I know who were educated in the US learned calculus instead of statistics. Because of this, I’m going to start at the ground level where Machine Learning and Statistics overlap and move forward from there. And if all my talk of math is freaking you out a bit my goal is that this series will not require anything beyond high school Algebra 1.
Descriptive Statistics Library
Several of the algorithms I hope to show use mean, standard deviation, and other basic descriptive statistics. Statisticians define some of these slightly differently than we learned in school. To simplify things I use the (descriptive_statistics)[https://rubygems.org/gems/descriptive_statistics] gem in Ruby. It extends Enumerable with the common descriptive statistics methods, so they are readily available and easy to use. All of my Ruby examples will use this library. In Python, I’ll use the scipy library.
A small, but important, note about the Ruby Descriptive Statistics library. In statistics, the way you calculate things like mean, variance, and standard deviation is different depending on whether you have data on every member of a population or just a sample. When you have all the data, you divide by the number of data points. When you only have a sample, you divide by the number of data points minus one. The reason for this is complicated and beyond the scope of my blog at this point but you can read more about it here. If you use Descriptive Statistics and notice your answers are different than ones you find in other sources, this might be the cause. You can fix this by putting the following code at the top of your file.
module DescriptiveStatistics
def variance(collection = self, &block)
values = Support::convert(collection, &block)
return DescriptiveStatistics.variance_empty_collection_default_value if values.empty?
mean = values.mean
values.map { |sample| (mean - sample) ** 2 }.reduce(:+) / (values.number - 1)
end
endLinear Regression
One of the basic things that Machine Learning tries to do is answer the question “What is the relationship between these pieces of data?” or perhaps more exactly “If I know part of the data can I figure out the rest?”. And the most basic technique for doing this is linear regression.
Regression is finding a line (not necessarily a straight line) that matches up to, or fits, some data relatively well. Once you have that line and an equation for it, you can use algebra to predict one value based on the other(s). This technique is frequently used in math, the sciences, economics, psychology, and shows up in newspapers and academic journals. I used one of the BigQuery public datasets to retrieve the number of babies born each year between 1969 and 2005 in the US. Here is the data in a basic plot.
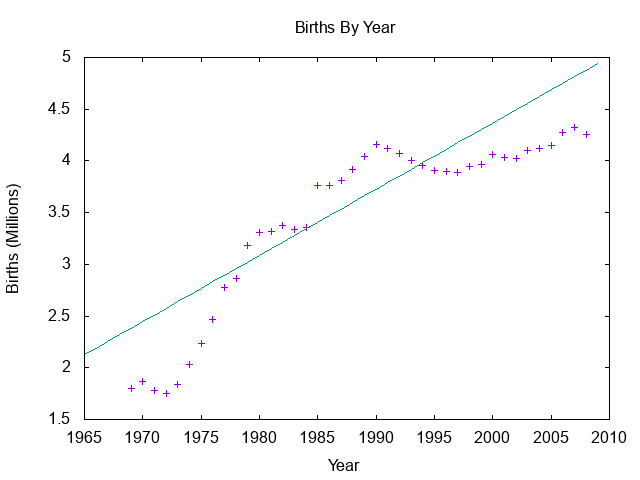
The chart above shows a linear regression. That means that I’ve assumed I can model the relationship between the x and y with a straight line. The equation for a line is y = Mx + B where M and B are numbers. The equation above shows y = 0.064x - 123.634.
Least Squares
To calculate the equation of a least squares line we need to calculate M and B in y = Mx + B. B, the y-intercept, is equal to r * (sd_x/sd_y). r is called Pearson’s correlation and sd_x and sd_y are the standard deviations of x and y. Pearson’s correlation is Cov(x, y) / (sd_x * sd_y) where Cov(x, y) is the covariance of x, y.
That’s a ton of letters, numbers, and math so let’s back up a bit and just look at the pieces of data we’ll need. First, we need the mean, or average, of the births and the years. Luckily, our library provides that for us.
births_mean = births.mean
years_mean = years.meanSecond, we need to know the standard deviation of each data set. If math class was a long time ago, standard deviation is how “spread out” the data is. If you imagine a bell curve a wide and short curve has a high standard deviation. A narrow and tall curve has a low standard deviation.
births_sd = births.standard_deviation
years_sd = years.standard_deviationCovariance
We also need to know the covariance of these two variables. Covariance is a measure of how much the variables “travel together.” If two data sets have high covariance, which the two data sets I’m using do, as one increases the other tends to increase and as one decreases the other tends to decrease. The covariance is calculated by first figuring out how much each point varies from the mean.
x_diffs = x.map { |x1| x1 - x.mean }
y_diffs = y.map { |y1| y1 - y.mean }Then you multiply the corresponding x’s and y’s and sum those together.
products = x_diffs.zip(y_diffs). map { |(x1, y1| x1 * y1 }
sum = products.inject(&:+)Finally, you divide by one less than the number of elements.
sum / (x.length - 1)Pearson’s Correlation and the Line
Once you have the covariance, you can calculate the correlation between the two data sets. I’m using Pearson’s Correlation. This value is frequently called r and is calculated by dividing the covariance by the product of the two standard deviations.
r = covariance(births, years) / (births_sd * years_sd) The correlation is a number between -1 and 1. A correlation of 1 means that the two data sets are strongly positively correlated: when one increases, the other increases. A correlation of -1 means the two data sets are strongly, negatively correlated: when one value increases the other decreases. A correlation of 0 means there is no linear correlation.
Those are all the values we need to calculate the regression line. The y-intercept of the line is equal to b = r * (x.standard_deviation / y.standard_deviation). The slope of the line is equal to y.mean - b * x.mean.
b = r * (births_sd / years_sd)
puts "b #{b}"
m = years_mean - b * births_mean
puts "m #{m}"
puts "Linear Regression Equation: y = #{m.round(3)}x + #{b.round(3)}"
>> y = 0.064x + -123.634There’s a lot of math, but it is all arithmetic once you break it down. And once we have the equation for the line we can predict how many births will happen in a given year. For the year 2050, we would expect to see 7.56 million births, for example.
Multiple Linear Regression
Linear regression isn’t limited to two variables. While it is harder to visualize, the same techniques work for 3 or more variables as well. Instead of doing the math on just x and y values just include as many other variables as you have in the appropriate places. You end up with an equation of the form y = b + m * x + n * z....
Next Time
The next post will cover the basics of clustering using K means. One of the nice things about K means is how easy it is to visualize which makes the math easier to understand.
The code for this post is located here.